
Bert là gì?
BERT là một mô hình xử lý ngôn ngữ tự nhiên không giám sát được đào tạo trước. BERT có thể làm tốt hơn 11 nhiệm vụ NLP (Natural Language Processing) phổ biến nhất sau khi tinh chỉnh. Về cơ bản đây là một bước tiến lớn cho việc công cụ Xử lý và Hiểu ngôn ngữ tự nhiên (Natural Language Processing and Understanding).
BERT là một khái niệm đơn giản nhưng lại mang lại hiệu quả cực lớn trong thực tế. Nó đã thu được kết quả tối ưu mới nhất cho 11 nhiệm vụ xử lý ngôn ngữ tự nhiên, bao gồm việc đẩy kết quả của nhiệm vụ GLUE benchmark lên 80.4%(cải tiến thêm 7.6%) và SQuAD v.1.1 với F1 score trên tập test đạt 93.2%(cải tiến thêm 1.5%), tốt hơn con người 2%.
BERT có tính hai chiều sâu sắc: Nó xem xét các từ trước và sau các thực thể và ngữ cảnh được đào tạo trước trên Wikipedia để cung cấp hiểu biết phong phú hơn về ngôn ngữ.
Mô hình kiến trúc của BERT
Kiến trúc của mô hình BERT là một kiến trúc đa tầng gồm nhiều lớp Bidirectional Transformer encoder dựa trên bản mô tả đầu tiên của Vaswani et al. (2017) và sự phát hành trong thư viện tensor2tensor.
Chúng ta sẽ gọi L là số lớp Transformer(blocks) được sử dụng với kích thước của các lớp ẩn là H và số heads ở lớp attention là A. Trong mọi trường hợp, kích thước của bộ lọc(filter size) luôn được đặt bằng 4H. Điều này có nghĩa là khi H = 768 thì filter size = 3072 và hoặc khi H = 1024 thì filter size = 4096.
Báo cáo chủ yếu lấy kết quả trên 2 kích thước mô hình
- BERT_{BASE}: L=12, H=768, A=12, Total Parameters=110M
- BERT_{LARGE}: L=24, H=1024, A=16, Total Parameters=340M
BERT_{BASE} đã được chọn để có một kích thước mô hình giống hệt như mô hình OpenAI GPT để nhằm mục đích so sánh giữa 2 mô hình này. Tuy nhiên, một cách đơn giản để so sánh, BERT Transformer sử dụng các attention 2 chiều trong khi GPT Transformer sử dụng các attention 1 chiều (không tự nhiên, không hợp với cách mà xuất hiện của ngôn ngữ), nơi mà tất cả các từ chỉ chú ý tới ngữ cảnh trái của nó.
Có một lưu ý dành cho mô hình trên
Một Transformer 2 chiều thường được gọi là Transformer encoder trong khi các phiên bản Transformer chỉ sử dụng ngữ cảnh bên trái thường được gọi là Transformer decoder vì nó có thể được sử dụng để tạo ra văn bản. Sự so sánh giữa BERT, OpenAI GPT và ELMo được hiện thị 1 cách trực quan dưới đây:
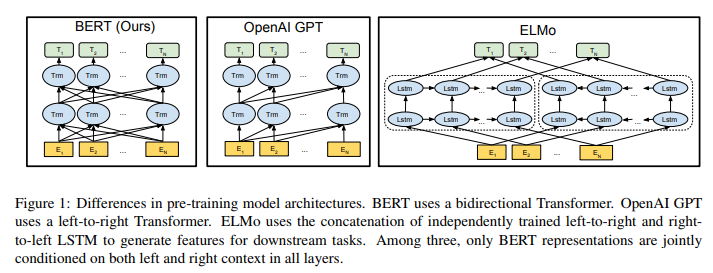
Tại sao BERT thông minh hơn các NLP hiện nay?
Google đã lấy văn bản trên Wikipedia và rất nhiều tiền cho sức mạnh tính toán (TPU mà họ tập hợp lại trong một pod V3) có thể cung cấp dữ liệu cho các mô hình lớn này. Sau đó, họ sử dụng một mạng thần kinh không được giám sát để đào tạo từ tất cả văn bản của Wikipedia để hiểu rõ hơn về ngôn ngữ và ngữ cảnh.
Điều thú vị về cách nó học là nó có độ dài văn bản tùy ý bất kỳ (điều này tốt vì ngôn ngữ khá tùy ý trong cách chúng ta nói) và nó chuyển nó thành một vector. Vectơ là một chuỗi số cố định. Điều này giúp ngôn ngữ có thể được dịch sang máy.
Điều này xảy ra trong một không gian n chiều thực sự hoang dã mà chúng ta thậm chí không thể tưởng tượng được. Đưa ngôn ngữ theo ngữ cảnh tương tự vào các khu vực giống nhau. Để có được BERT thông minh hơn và thông minh hơn, tương tự như Word2vec, hãy sử dụng một chiến thuật gọi là Masking. BERT là một mô hình hai chiều nhìn vào các từ trước và sau từ ẩn để giúp dự đoán từ đó là gì.
Ví dụ
Với câu: “con_mèo của tôi đẹp quá” Từ được chọn để mask là từ “đẹp“.
- Thay thế 80% từ được chọn trong dữ liệu huấn luyện thành token [MASK] –> “con_mèo của tôi [MASK] quá“
- 10% các từ được chọn sẽ được thay thế bởi 1 từ ngẫu nhiên. –> “con_mèo của tôi máy_tính quá“
- 10% còn lại được giữ không thay đổi –> “con_mèo của tôi đẹp quá“
Điểm yếu của BERT
Allyson Ettinger đã viết bài báo nghiên cứu thực sự tuyệt vời này có tên là “What BERT Can’t Do”. Điều đáng ngạc nhiên nhất từ nghiên cứu của cô ấy là lĩnh vực chẩn đoán phủ định này. Có nghĩa là BERT không giỏi trong việc hiểu về phủ định hoặc những thứ không phải vậy. Ví dụ, khi đầu vào với Robin là một… Nó dự đoán con đà điểu, điều đó đúng, điều đó thật tuyệt. Nhưng khi nhập vào Robin không phải là… Nó cũng là loài chim tiên đoán. Vì vậy, trong trường hợp BERT không nhìn thấy các ví dụ hoặc ngữ cảnh phủ định, nó vẫn sẽ gặp khó khăn khi hiểu điều đó. Có rất nhiều điều thực sự thú vị trong nghiên cứu của Allyson, rất khuyên bạn nên xem qua.
Tối ưu hóa thuật toán cho BERT
Danny Sullivan – đồng sáng lập của trang Search Engine Land chia sẻ “Không có gì để tối ưu cho BERT cả, và cũng không có gì để mọi người phải tư duy lại cả. Những nguyên lý nền tảng mà chúng ta theo đuổi để tạo ra kết quả tích cực cho những nội dung tốt vẫn không thay đổi.”
Từ trước đến nay, lời khuyên của Google nếu muốn thăng hạng tốt luôn là hãy nghĩ đến người dùng và tạo ra các nội dung thỏa mãn ý định tìm kiếm của họ. Vì BERT được thiết kế để diễn giải ý định đó. Vậy nên không có gì khó hiểu khi Google vẫn nhất quán với quan điểm của mình: hãy cung cấp cho người dùng những gì họ muốn.
“Tối ưu hóa” giờ đây nghĩa là bạn có thể tập trung và đầu tư hơn vào việc viết nên những nội dung tốt, rõ ràng, thay vì thỏa hiệp giữa việc tạo ra nội dung cho đối tượng mục tiêu của bạn và việc đặt các từ ngữ trong câu như thế nào cho các bộ máy.
Tổng kết
Cân nhắc những thứ như đoạn trích nổi bật; xem xét những thứ như tính năng SERP. Điều này có thể bắt đầu có tác động rất lớn trong không gian của chúng ta. Vì vậy, điều quan trọng là phải nắm bắt được thông tin về nơi mà tất cả đang hướng đến và những gì đang diễn ra trong lĩnh vực này.